
Statyczna analiza kodu, czyli jak komputer może szukać błędów
03.02.2010 - Krzysztof Skrzętnicki
  Pisanie kodu to proces długi i skomplikowany. Chwila nieuwagi i nieszczęście gotowe - pojawia się błąd. Czy da się choć część z nich wykryć automatycznie? Przekonajmy się. Odpowiedź na to pytanie jest twierdząca. Najprostszym przykładem automatycznego sprawdzania poprawności programu jest wbudowany w kompilator wielu języków system kontroli typów. W zależności od języka system ten jest bardziej lub mniej zaawansowany. W przypadku klasycznego, niskopoziomowego Assemblera nie mamy kontroli typów wcale (choć i tutaj prowadzi się pewne eksperymenty, patrz język TAL). W językach wyższego poziomu bywa różnie. Najbezpieczniejszy kod można uzyskać w językach opartych o typy zależne (ang. dependent types), takich jak Agda czy Cayenne. Umożliwiają one napisanie kodu, który w trakcie kompilacji będzie sprawdzony pod kątem niemal dowolnych błędów. Niestety pisanie w tych językach często niesie ze sobą duży narzut dodatkowej pracy, którą musi wykonać programista. Bywa jednak, że piszemy w języku o znacznie prostszym systemie typów, takim jak C. Powodów może być wiele, z czego najprostszym jest wydajność: język ten jest dobrze zrozumiały i łatwo można w nim napisać kod, który będzie bardzo szybki. Pisanie w C niesie jednak ze sobą pewne niebezpieczeństwa. Jest wiele błędów, które można popełnić. W szczególności bardzo często popełniane są następujące błędy:
Choć ostatni błąd sam w sobie nie powoduje błędnego funkcjonowania w programie, z dużym prawdopodobieństwem w okolicy mimo wszystko coś jest nie tak. Oto przykład:
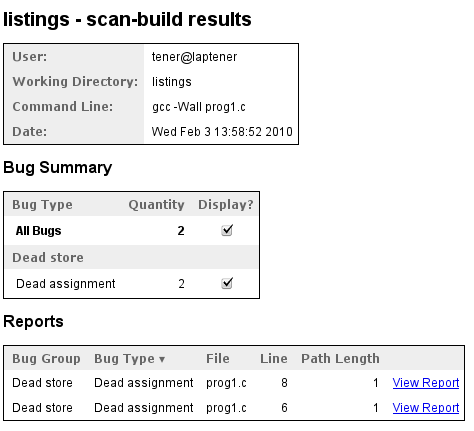
W powyższym kodzie łatwo zauważymy, że wynik jest wyliczany przy użyciu złych zmiennych. Ale w funkcjach bardziej skomplikowanych może się zdarzyć, że taka sytuacja przejdzie niezauważona. Ten i inne błędy może nam pomóc wyłapać specjalne oprogramowanie, służące do analizy kodu źródłowego. Clang kontra GCCNajpopularniejszym kompilatorem języka C na platformę Linux jest Gnu C Compiler, czyli GCC. Kompilator ten obsługuje także inne platformy i języki programowania. Wśród nich znajduje się komputery firmy Apple działające pod systemem OS X i ulubiony język tej firmy - Objective C. Aktualni deweloperzy GCC nie uznają obsługi tego środowiska za zadanie priorytetowe. Koniec końców Apple zdecydowało się na stworzenie własnego kompilatora o nazwie Clang. Razem z nim stworzono system narzędzi do analizy kodu. Z poziomu użytkownika widoczne są dwa: scan-build (do kompilowania i analizy kod) i scan-view (do wygodnego przeglądania raportów tworzonych przez scan-build). Zobaczmy, co powie scan-build na temat powyższego kodu: $ scan-build gcc -Wall prog1.c ANALYZE: prog1.c policzXYZ prog1.c:6:4: warning: Value stored to 'v1' is never read v1 = x1*(x1*(x1 + 5) + 3) + 1; ^ ~~~~~~~~~~~~~~~~~~~~~~~~ prog1.c:8:4: warning: Value stored to 'v2' is never read v2 = x2*(x2*(x2 + 5) + 3) + 1; ^ ~~~~~~~~~~~~~~~~~~~~~~~~ ANALYZE: prog1.c main 2 diagnostics generated. scan-build: 2 bugs found. scan-build: Run 'scan-view /tmp/scan-build-2009-12-12-10' to examine bug reports. Odpowiedź kompilatora jest zgodna z naszą wiedzą: poprawnie zauważył on, że zmienne v1 i v2 po użyciu nigdy nie są używane. Jednocześnie GCC pomimo przekazania opcji A tak po ludzku?Choć powyższe komunikaty są w miarę czytelne, to jednak w gąszczu innych wiadomości mogą się zgubić. Istnieje jednak Narzędzie to uruchamiamy poleceniem: $ scan-view /tmp/scan-build-2009-12-12-10 Alternatywnie możemy przekazać '-V' jako pierwszą opcję do scan-build. Początkowo widzimy listę wszystkich błędów umieszczonych w raporcie:
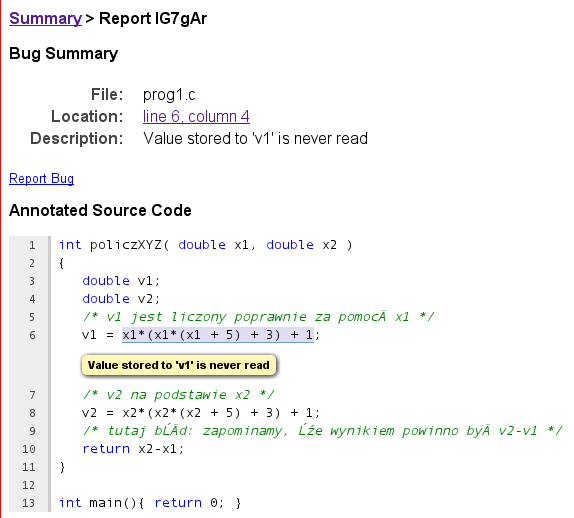
Po kliknięciu na pierwszy z nich zobaczymy następujący widok:
Mamy więc mniej więcej tą samą informację, ale dla odmiany występuje ona w kontekście całego kodu. Dzięki temu łatwiej jest analizować raport. (3 ocen) |
Pod patronatem:



Informacje
- O portalu
- Autorzy
- Mapa portalu
- Zgłoś błąd
Copyright © 2008-2010 Wrocławski Portal Informatyczny
design: rafalpolito.com